Drones worden al jaren gebruikt om inspecties mee uit te voeren. Bij deze inspecties is men vooral geïnteresseerd in de delen waar zich onregelmatigheden voordoen, ook wel “anomalieën” genoemd. Denk maar aan een scheur in beton, afbladdering van verf, roestplekken of kapotte zonnepaneelmodules. In dit artikel leer je meer over de toepassingsgebieden van anomaliedetectie in het visie-domein en welke technieken gebruikt worden.
Introductie
Vanuit wetenschappelijk standpunt zijn anomalieën “waarneming in een dataset die inconsistent lijken te zijn met de rest van die dataset” – Johnson 1992. “Een anomalie is een waarneming die zo sterk afwijkt van de andere waarnemingen dat de verdenking rijst dat een ander mechanisme haar heeft gegenereerd” – Hawkins 1980. Anomalieën zijn gebeurtenissen die afwijken van de norm, onregelmatig voorkomen en niet passen in de rest van het “patroon”.
Deze kunnen in verschillende domeinen voorkomen zoals bijvoorbeeld grote beursdalingen en -winsten als gevolg van wereldwijde gebeurtenissen, defecte producten in een fabriek of op een transportband of besmette laboratoriummonsters. In het visie-domein worden anomalieën op een (camera-)beeld opgespoord. Dat kan gaan om bijvoorbeeld het opsporen van afwijkingen in muren van gebouwen of in industriële onderdelen. Het opsporen van anomalieën op basis van camerabeelden wordt meer en meer toegepast onder andere voor het garanderen van kwaliteit van massaproductiegoederen waarbij het sneller, betrouwbaarder en goedkoper is dan dit door mensen te laten doen.

Technieken
Verschillende technieken worden toegepast om anomalieën in camerabeelden op te sporen:
- Traditionele beeldverwerkingstechnieken zoals randdetectie, kenmerkdetectie en het meten van bijvoorbeeld grootte, kleur, positie, omtrek, rondheid, vorm … worden gebruik om een object te beschrijven en op basis hiervan te beslissen of het normale of afwijkende waardes heeft. Het voordeel van deze techniek is dat er geen voorafgaande training vereist is. Het nadeel is echter dat elke toepassing een nieuwe oplossing op maat vereist. Indien in de toepassing de variaties gekend en beperkt zijn, kan deze techniek een robuuste oplossing bieden.

- Machine Learning algoritmes gebruiken rekenintensieve methodes om informatie rechtstreeks uit gegevens te “leren” zonder te vertrouwen op een vooraf bepaalde vergelijking als model. De hoeveelheid maatwerk is dus beperkter. Deze techniek vereist ook slechts een beperkte hoeveelheid aan trainingsdata maar is daarna wel enkel maar toepasbaar op de specifieke case waarop het getraind is. Wanneer de toepassing veel variaties heeft die niet op voorhand gekend zijn en daarnaast de hoeveelheid gelabelde data en beschikbare rekenkracht enigszins beperkt is, is deze techniek het meest aangewezen.
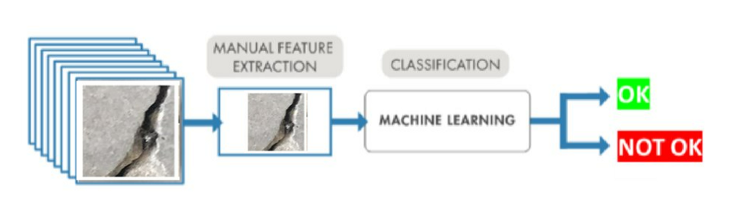
- Deep Learning gebruikt een neuraal netwerk om onregelmatigheden op te sporen. Om dit netwerk te trainen zijn echter een grote gedocumenteerde dataset nodig en een stevige hoeveelheid rekenkracht. Het voordeel is dan wel dat het resultaat toepasbaar is op een brede waaier aan toepassingen met vooraf ongekende variaties. Deze techniek kan best toegepast worden wanneer er veel rekenkracht en -tijd beschikbaar is en er veel gelabelde data beschikbaar is.

Trainen
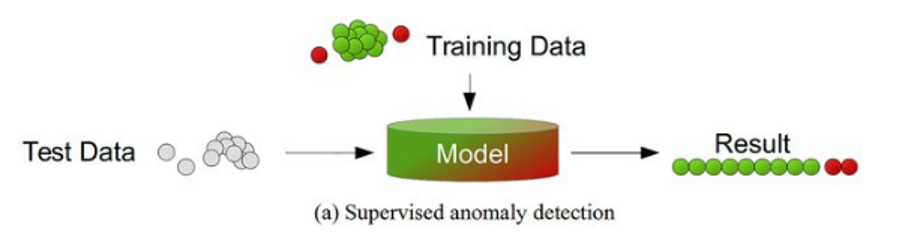
De data voor het trainen van de zelflerende algoritmes kan op verschillende manieren aangereikt worden. In het beste geval is de dataset netjes voorbereid en gestructureerd met alle datapunten gelabeld als “goed” of “slecht” (anomalie) en kan “supervised learning” toegepast worden. Populaire zelflerende algoritmes voor gestructureerde gegevens zijn onder andere support vector machine learning, KNN, Bayesiaanse netwerken en beslissingsbomen.
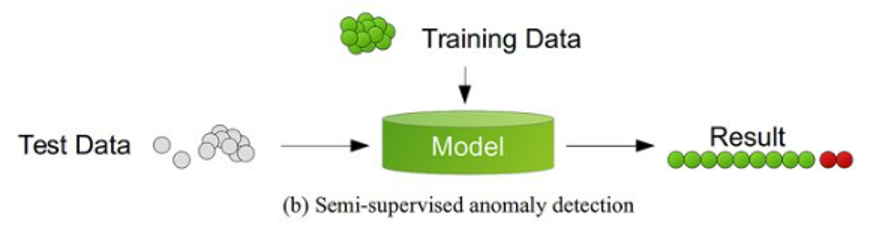
Soms is er enkel “goede” data beschikbaar voor het trainen van het algoritme zal op basis hiervan een model opgesteld worden dat vervolgens in staat is afwijkingen te detecteren op nieuwe data waar anomalieën in zitten. Deze techniek van trainen heet “semi-supervised learning”. Populaire algoritmes hiervoor zijn onder andere auto-encoders, één-klasse SVM’s, Gaussian Mixture Models en Kernel Density Estimations.
Tot slot kan het zijn dat de data wel bestaat uit “goede” en “slechte” data maar deze nog helemaal niet gelabeld zijn. Hierbij moet het zelflerende algoritme zelf eerst proberen de data te clusteren in goed of slecht op een “non-supervised” manier. Technieken die hiervoor veelal gebruik worden zijn SOM, K-means, C-means, EM, ART en one-class support vector machine.

Toepassingen binnen de drone sector
Anomaliedetectie op beelden die door een drone gemaakt worden, kan op een brede waaier van toepassingen ingezet worden. Een eerste voorbeeld is bijvoorbeeld scheurdetectie en lokalisatie van scheuren op een 3D-model van een betonstructuur waarbij in een eerste stap de opgenomen data na de vlucht door het algoritme geanalyseerd wordt maar vervolgens het algoritme ook sneller gemaakt werd zodat reeds tijdens het vliegen de piloot geassisteerd kan worden in het zoeken naar scheuren door deze in het beeld aan te duiden.

Een tweede mogelijke toepassing is wat verregaander waarbij een hele situatie in beeld gebracht wordt en gekeken wordt naar afwijkingen in de hele situatie. Een concreet voorbeeld hiervan is een verkeerssituatie waarbij het algoritme kijkt of er mensen, fietsers of voertuigen zich op privéterrein begeven, zich niet aan de verkeersregels houden en of er verdachte of ongekende voorwerpen zich in beeld bevinden. Naast de dronebeelden kan het algoritme ook extra informatie binnenkrijgen van bijvoorbeeld de stand van de verkeerslichten of GPS posities van de voertuigen.
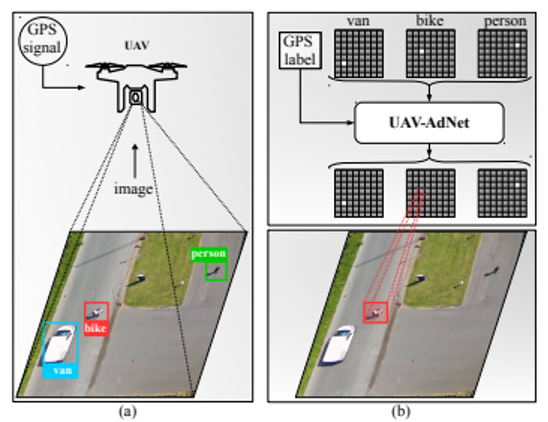

Nauw verbonden met de voorgaande toepassing kan anomaliedetectie ook in een surveillancecontext toegepast worden. De prestaties van de algoritmes hiervoor zijn echter nog niet helemaal bewezen. Zo zijn situaties die het tijdens het trainen nooit aan bod zijn gekomen zeer moeilijk te interpreteren voor de algoritmes. Langs de andere kant is het ook niet haalbaar om alle mogelijke situaties in het trainingsdataset aan bod te laten komen.

Een laatste voorbeeld is het automatisch interpreteren van drone infrarood inspectiebeelden van PV-installaties is vanwege de grote meerwaarde intensief onderzocht afgelopen jaren en wordt ook met succes toegepast. Echter, de nauwkeurigheid, robuustheid en generalisatie van de ontwikkelde algoritmes zijn nog steeds de belangrijkste uitdagingen, vooral bij het omgaan met verschillende types van fouten.

Samengevat
In dit artikel vond je antwoorden op volgende vragen:
- Wat is een anomalie/onregelmatigheid en wat is een “Anomalie Detectie” systeem?
- Welke technieken binnen het visie-domein gebruikt kunnen worden en welke het meest geschikt is in welk geval.
- Wat het verschil is supervised, semi-supervised, of non-supervised technieken voor het trainen van de zelflerende algoritmes?
Interesse, vragen of suggesties: de onderzoekers van Flanders Make staan u graag ten rade!
Auteurs: Merwan Birem en Bart Theys